Workday Adaptive Planning allows its users to have a single source of truth regarding company data thanks to its ability to leverage many integrations across many systems. These integrations provide new inputs to models and allow greater accuracy of outputs. In order to provide the most accurate forecasts, many clients have begun to leverage Workday Adaptive Planning’s Snowflake Integration to bring new, more granular, data into Adaptive.
According to Snowflake, “A data warehouse is a relational database that is designed for analytical rather than transactional work. It collects and aggregates data from one or many sources so it can be analyzed to produce business insights. It serves as a federated repository for all or certain data sets collected by a business’s operational systems.” In today’s article, we will discuss the three methods for connecting these two systems.
Fetching data from SnowFlake into Workday Adaptive Planning
As of April 2023, you have several options to choose from in order to integrate Workday Adaptive Planning and Snowflake.
Here are the ways to pull/push data between Adaptive and Snowflake:
- You can use Adaptive’s native Integration Module (Discussed in the article below)
- Use workflow automation third-party tools (ie. Tray.io, Workato, Boomi…) that leverage Snowflake’s and Adaptive’s APIs (This requires you to pay a fee + manage another tool)
- Write your own script to pull/push data between the 2 systems using their APIs (This requires you to have some programming experience or have a programmer on staff and is cumbersome to maintain)
Below we will discuss the advantages of using Adaptive’s integration module as well as list the pros/cons of each method.
Using Workday Adaptive Planning’s Integration
When integrating Workday Adaptive Planning and Snowflake, using Adaptive’s integration module, you have three possible methods, using the following Data Sources:
- JDBC
- ETL (Scripted Data Source)
- CCDS (Custom Cloud Data Source)
- You will fetch your Snowflake data from a file sitting in an SFTP server or cloud storage such as AWS S3 (S3 being a preferred method)
- As of today, you can’t make HTTPS web requests from CCDS to Snowflake!
While each setup has pros and cons (explained below), our recommendation is to do a Custom Cloud Data Source with a CSV dump (unload) to AWS S3.
So far, this is the easiest way to set up the integration with little coding required, and Snowflake has an easier setup with AWS S3 (easy export, format + scheduled tasks) → See posted Snowflake articles related to this process down below (unload of data to storage + format + task schedule)
❗Please note that you can’t do HTTPS requests from Adaptive to Snowflake.
🥜Adaptive’s library is limited for HTTPS requests and it can’t work with Snowflake as of now.
→ I posted feedback for their roadmap: to develop a Native integration with SnowFlake (just like with NetSuite) or add a library related to Snowflake (just like they have one for S3 for ex.)
Essentially: The HTTPS library developed by Adaptive to make HTTPS requests is very simplistic and not comprehensive enough to be used with Snowflake. And you can’t add external JavaScripts libraries in your JS scripting platform in Adaptive. Which leaves us with impossible usage.
Possible data sources to connect to SnowFlake from Adaptive:

CCDS with SFTP of AWS S3 Workflow
(Preferred method)
⧱ High-level workflow:
Your IT/Data team writes a script to call the Snowflake queries → saves CSV output into an SFTP server or AWS S3. → Adaptive’s simple JavaScript fetches the file and pushes it to your Data source (as a table) → from here you can set up your integration/mapping as usual!
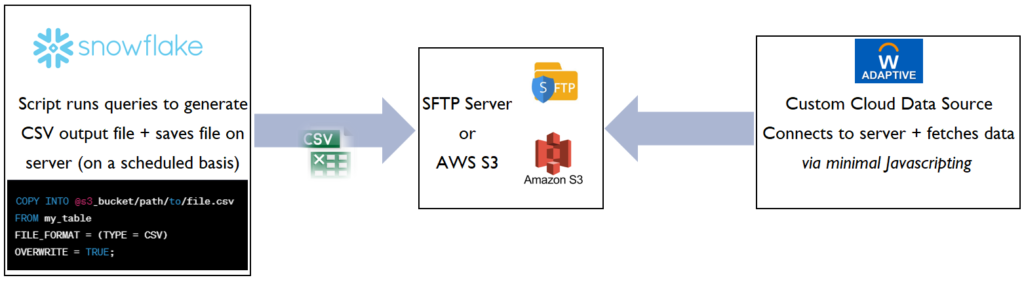
Note: Snowflake’s key documentation links are indicated below
Pros and Cons of each Data source
| Data source type | Requires Agent* | Requires Pentaho Kettle | Requires Javascripting | Other / Comments |
| JDBC | Yes 🔴 | No 🟢 | No 🟢 | IT needs to install the Data Agent + drivers to manage the connection. But no JavaScript coding. Recommended but requires an install and setup on a server. A bit of an old way to do things. Sometimes the Agent service may stop running (needs a reboot, increase of memory, etc.) |
| ETL | Yes 🔴 | Yes 🔴 | No 🟢 | Requires install of Data Agent + Pentaho ETL. Your IT team creates a script that fetches the data from SF and saves it on the server where the agent runs. Pentaho will transform the file and Adaptive will then fetch it. Definitely not recommended. Absolutely not optimal! |
| CCDS | No 🟢 | No 🟢 | Yes 🔴 | Your Data / Cloud team writes a script that runs the queries in Snowflake + saves it in AWS S3 or an SFTP (can be scheduled). Snowflake integrates really well with AWS S3. Minimal Javascripting in Adaptive to fetch the CSV file. Recommended and preferred: simpler workflow. Fastest setup for IT + Adaptive team. |
*Data Agent – More info about Data Agents, per Workday Adaptive’s documentation:
Data Agents
The data agent is a component of Integration that runs on an Adaptive Planning customer on-premises server. The data agent extracts information from a JDBC-compliant database or a custom-scripted data source. Data agents can also export data from Adaptive Planning. The data agent requires a computer running Windows deployed behind a customer firewall, and runs as a hosted service. The data agent manages access to on-premises applications as well as connections to Adaptive Planning on the cloud.
The Data Agent Service (the Agent Service) manages the data agents. This service runs as a Windows Service and launches a Java application installed behind the customer’s firewall. The Agent Service long polls the Adaptive Planning Gateway. The gateway server brokers communication through the firewall to on-premises instances of the Agent Service. This gateway receives requests from Adaptive Planning servers on behalf of all data agents hosted by that instance of the service. Each installed instance of the Agent Service can host multiple data agents.
The installation includes the Data Agent Service Manager, a desktop utility the customer uses to initially setup and configure the Agent Service. The installation optionally includes Pentaho Kettle and Spoon, the Kettle ETL Designer. If the optional Pentaho Kettle components get used, the Agent Service manages a pool of Kettle ETL execution instances (job runners). Each execution instance is a Java virtual machine running in its own process. The Agent Service delegates any Kettle ETL scripts that launch to a free job runner. Adaptive Planning provides plugins to enable design-time connectivity between the Spoon environment and Adaptive Planning Integration. These plugins allow for authenticating into a cloud instance of Adaptive Planning, publishing scripts to the cloud, and testing the script-based integration from within the Kettle UI. Note that the optional Pentaho components are needed only if there is a requirement to use a Pentaho Kettle script to extract data. These components are not needed if the data agent extracts data out of JDBC-compliant databases using Adaptive Planning JDBC data sources.
The on-premises data agents get managed and controlled from the cloud using the agent UI. The agent UI is part of the Adaptive Planning data designer, accessed through a web browser. When an agent is created in the data designer, the customer can download and install the latest version of the data agent, along with the optional Pentaho Kettle components. The agent UI shows the current status and version details of the agents and allows the customer to provision/unprovision/suspend/resume data agents. The customer can also upgrade to a newer version of the data agent through the agent UI. ”
Snowflake’s key documentation pages
Here are the key Snowflake’s links to its documentation:
- Unload your Snowflake data into cloud storage: HERE
Unload to AWS S3: HERE
- Available formats – we want CSV: HERE
- Schedule your data unload task: HERE